May I suggest something?
Search, sure, but what else?
I don’t read newspapers. I haven’t in a while. Like many people, I prefer not to have half a tree stuffed into my mailbox every day. I don’t want to spend time going through a medium the size of a bed sheet in a linear fashion to find what’s important and interesting to me.
I do, however, have digital subscriptions. I use them to keep myself informed about “important” events on a daily basis and occasionally to call up specific background information on certain topics.
So far, so normal. The trend is moving away from “prescribed structures” towards individual retrieval anyway. Whether that manifests in TV vs. Netflix, vocational training vs. online courses, or even daily “wallpaper” vs. news portal.
A prerequisite for this kind of consumption is searchability. I search for specific topics, authors, geographies. This is irreplaceable, otherwise what should be quick information becomes tedious excavation.
Fortunately, we’ve reached the point where almost every newspaper portal offers a search function, but a closer look often reveals a pretty poor implementation:
Yes, of course, dear newspapers, you can expect me to know how to spell “Ukraine”, but do you have to make me type it out completely before I find anything at all?
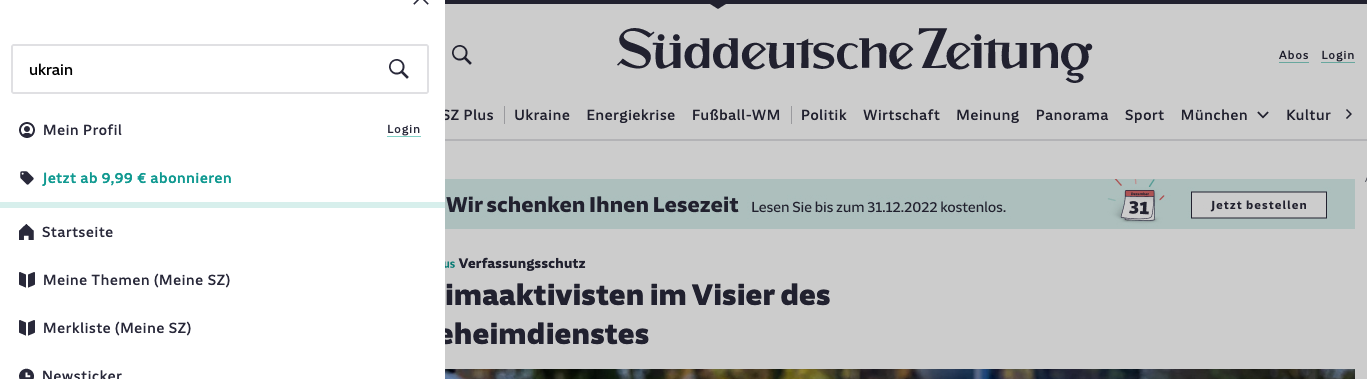
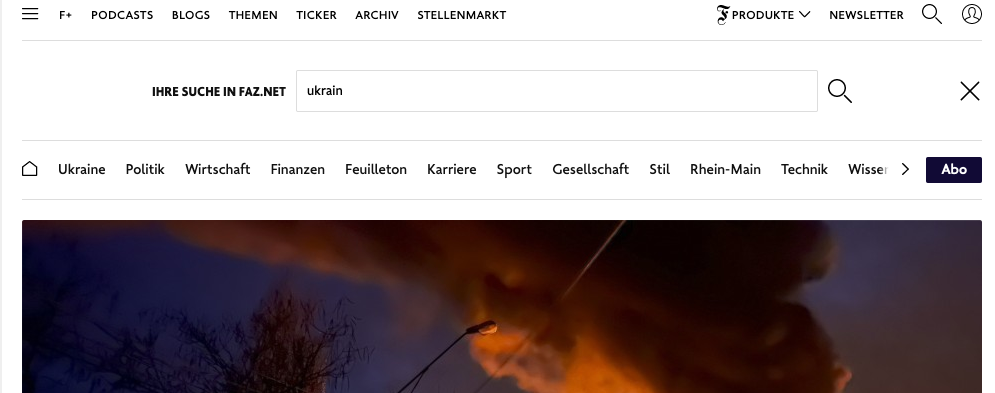
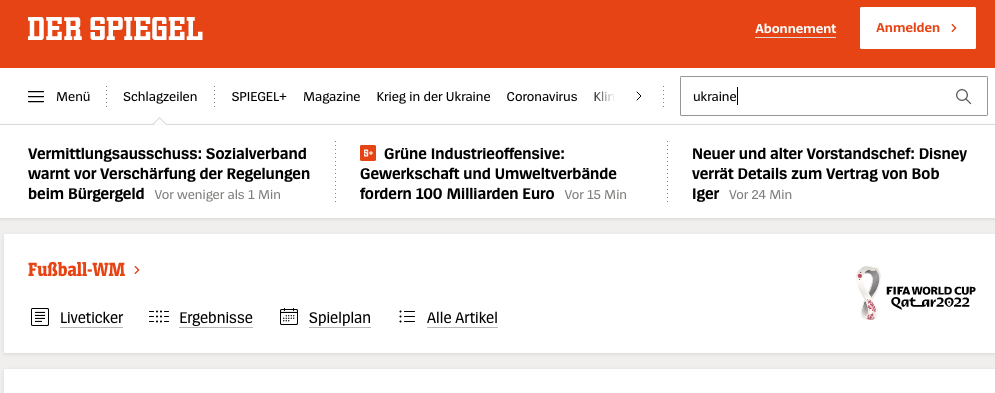
Wherever you go, it’s the same sad story: even the biggest German newspaper portals don’t offer meaningful suggestion lists.
Searching is too much work
What a missed opportunity!
Firstly, you could have saved me so much work and thus made me much more interested in your portal.
And yes, I know how to spell “Ukraine”, but let’s be honest, with ”Wolodymyr Selenskyj” we all start having doubts.
How enormously helpful would something like this be:
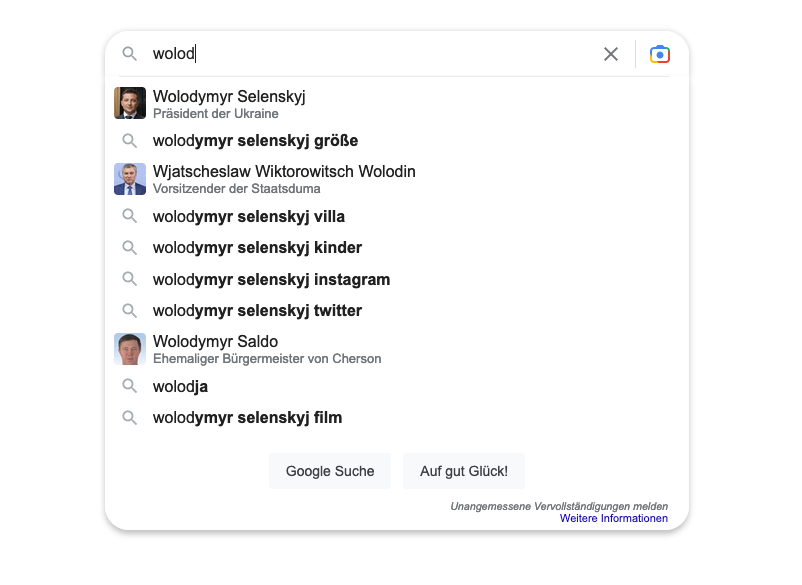
But the missed opportunity does not only consist in helping my clumsy spelling of Slavic names:
There is no better way to get more relevance out of a search engine than to feed it with more search terms.
The Google list is also a good example of this. I’m probably looking for something more specific than “Ukraine” or “Selenskyi,” for example, rather “latest developments in the Ukraine war” or “Selenskyi’s comment on the defensive missile.” But how often do we really type all those words out, especially on a mobile device? No, we usually stick with the statistically normal 1.5 search words.
Show me the way
Here lies the second missed opportunity: to take the user by the hand, to provide them with more relevant results by suggesting more relevant, specific terms and phrases, perhaps even combinations that they haven’t specifically thought of yet, but that are answerable with the content on the portal.
The Neue Zürcher Zeitung does it a bit better - albeit transliterating “Selenski” instead of “Selenskyj” and not accepting other spellings.
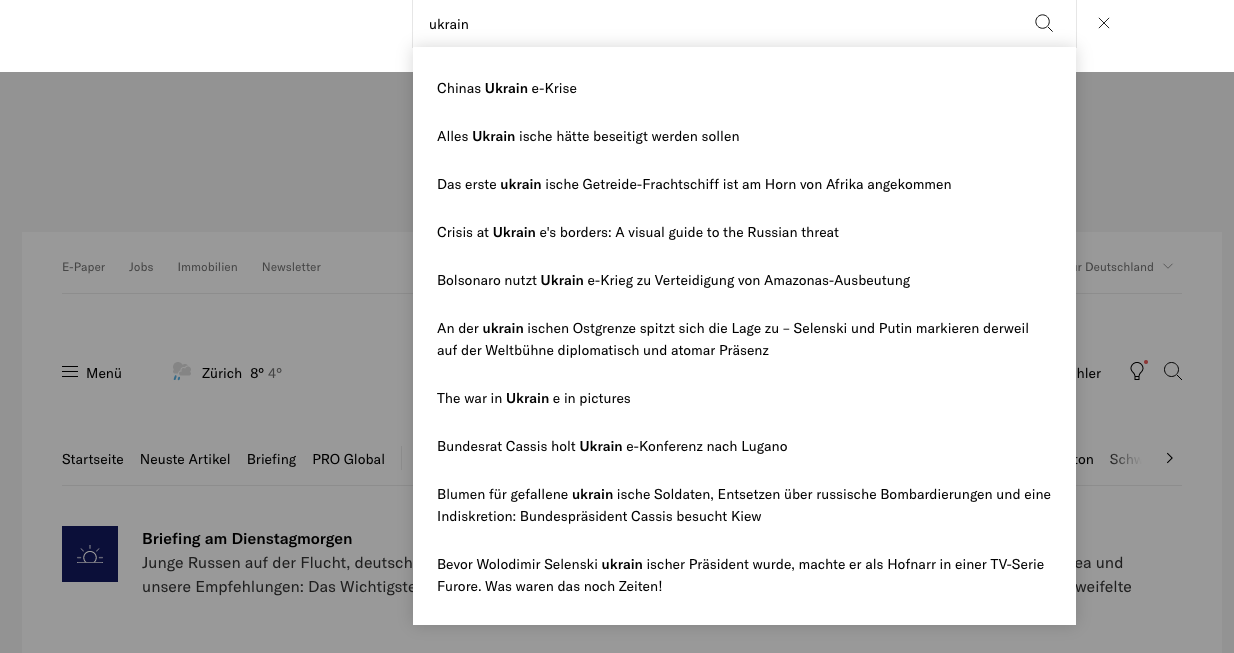
But this suggestion list is actually also just a list of article titles containing the letters entered. As mentioned, there is no tolerance for errors (although one cannot really speak of an “error” when transliterating names originally written in Cyrillic) and no suggestions that try to “fathom” the user’s search intention.
The NZZ list is no great enlightenment in this respect either. Which of these suggestions do I click on? Presumably, each one leads to exactly one article. Which of these articles is more up-to-date, longer, shorter, an overview of the topic, a live ticker? Hello? I’d like half a pound of user guidance, please. Then feel free to throw in an ad or two, too.
Handrail and highlights
What do I actually want?
Suggest, autocomplete, search suggestions or whatever you want to call them are not just “faster search”. They should be based on a logical aggregation of content, not the content itself.
I don’t just want article headings suggested, I want topics, countries, authors - all categories that are relevant.
The result of a suggest function is a search query, not a list of articles. Without this extra layer of abstraction, the function loses much of its value.
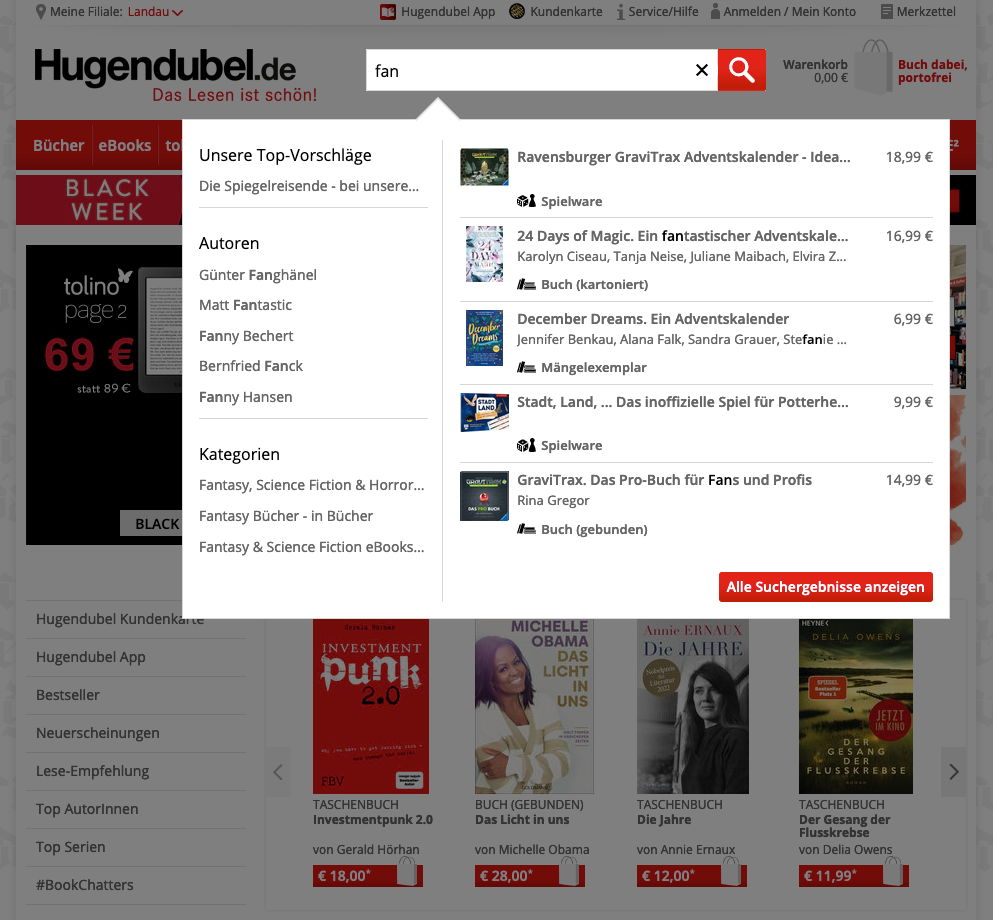
An example of how to get a lot of things right is Hugendubel’s Suggest list:
Which categories are relevant for a media retailer?
- Authors / Artists
- Title
- Genres / Topics
- Actions
And it is from these categories that I get the most relevant (e.g., highest circulation) suggestions.
Specific book titles are again direct links to the article, but authors and genre take me to a results list where I can look around further.
A Suggest feature that tells me what’s searchable, does a lot of the work for me, and yet doesn’t patronize me - it’s not that difficult.
