ChatGPT "knows" nothing

LLMs lie
"We don't build applications that extract knowledge from language models." This is one of our guiding principles. Customers are often surprised by this statement, but anyone who is familiar with large language models inevitably comes to the same conclusion: language models are incapable of reliably reproducing knowledge to the point of uselessness, even if this very knowledge was contained in their training data.
Nevertheless, many of the countless prompts and applications that we are presented with every day are designed to do just that: Without further input, ChatGPT or Gemini or Claude are used to produce "facts". In my view, this is careless to the point of being irresponsible; even specifically retrained language models are not reliable experts.
Hallucinations are not a minor problem that can be dismissed as an insignificant side effect. Hallucinations will not disappear even if "the models keep getting better". As long as the technical approach remains the same, hallucinations will remain. They occur more frequently where the training set was sparse, e.g. when moving out of the English language area in OpenAi and when there were only a few texts on a topic in the training corpus. Facts that are frequently represented in the training set can be reliably queried, while those that are less frequently represented are distorted. In the case of facts that are not represented at all, alternative statements are made up on the fly.
Of course, this problem does not only affect GPT, but all Large Language Models. The smaller the model, the more pronounced the effect generally is.
One question - many wrong answers
To make this a little more tangible, we have once again put a fact question through several language models. To be fair, we always use the same question, namely: "Who was Georg Lohmeier".
As not everyone may know the man, here is the first section of his (German) Wikipedia page as a reference:
Georg Lohmeier, pseudonym Tassilo Herzwurm (* July 9, 1926 in Loh; † January 20, 2015 in Munich) was a German writer, playwright, director and actor. He is the author of various plays and television series such as Königlich Bayerisches Amtsgericht or Zwickelbach & Co. and several plays for the Komödienstadel. He was briefly head judge on the show Dalli Dalli.
Older people will remember the "Königlich Bayerische Amtsgericht", younger people won't even remember "Dalli Dalli". Nevertheless, he is definitely a public figure and there are more than enough newspaper articles, books and pictures about him.
It can therefore be assumed that the essential facts about him are probably also represented in the training sets of most Large Language Models, although certainly not to any great extent.
Assuming that an LLM is suitable as a "knowledge repository", it must also be possible to retrieve this knowledge reliably.
Let's first take a look at ChatGPT 3.5 (the currently freely available and therefore most frequently used model).

Georg Lohmeier ends up in the right category, but after that it's all downhill:
- Wrong date of birth
- Wrong place of birth
- Wrong date of death
- Wrong works
- Awards wrong
Maybe one has to pay to get the facts?
ChatGPT 4 actually gives a - slightly - better answer:

But:
- Wrong date of birth (although somewhat closer to the truth)
- Wrong place of birth
- Wrong date of death
At least the main work is correct here and the activities are also shown accurately. But why it is so difficult to get the dates fully correct remains a mystery.
Let's turn to the newcomer: Mistral. The company headquarters in Paris suggests a somewhat more European focus and German-language documents (certainly including Wikipedia) are also clearly part of the training data.
However, the result is sobering:
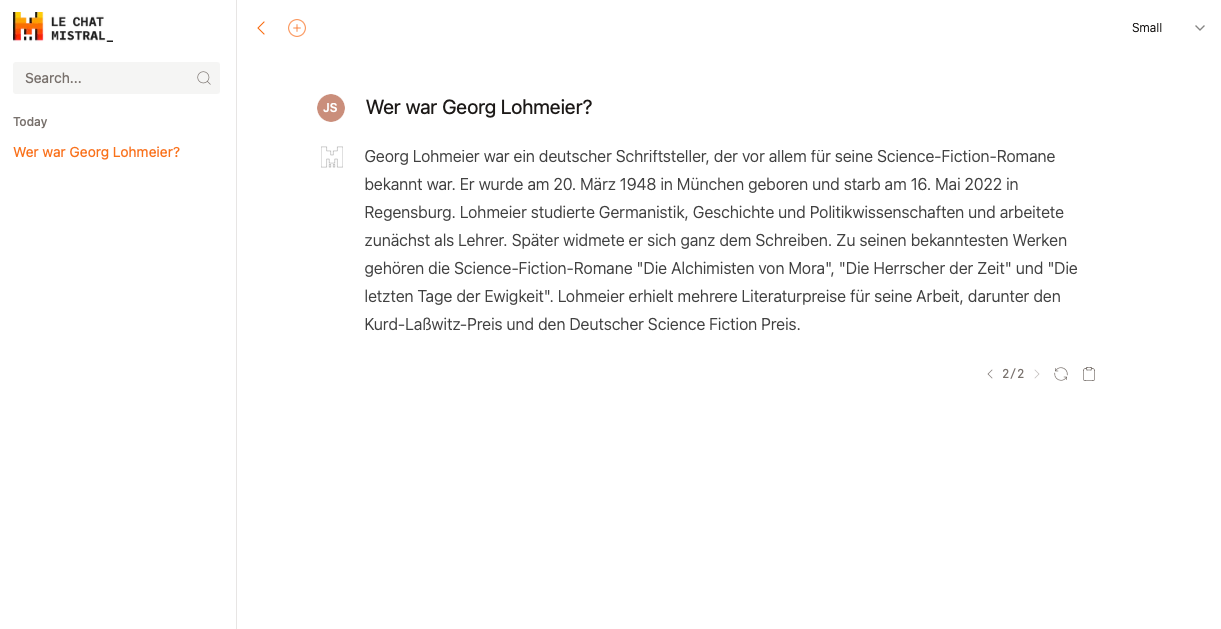
The "small" model starts lying after the sixth word ("writer") and doesn't stop until the end. That's all that needs to be said.
The larger model was slightly better with ChatGPT, and with Mistral this is no different:
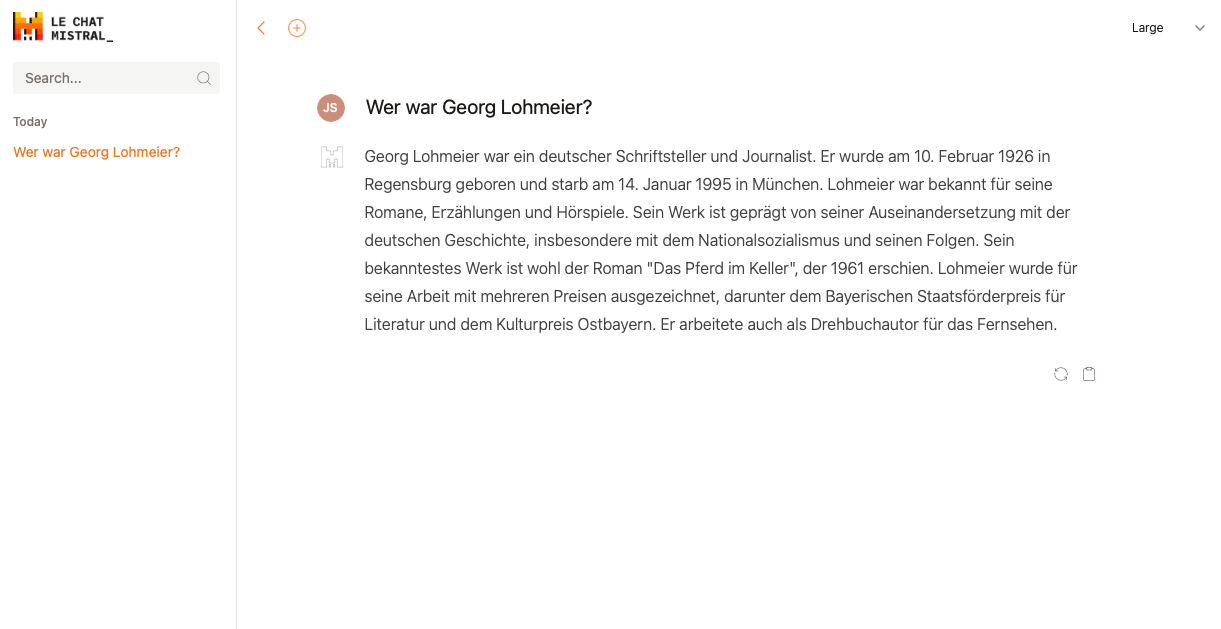
The "large" model lies its way to new heights from word eight onwards, but in the last sentence it does let slip a true fact. The date of birth at least contains the correct year. Well, Mistral is still a bit of an underdog, focused on an "open approach" - at least for the moment. Perhaps the model quality here is not quite up to par yet.
So what about Anthropic, whose focus is on safety and alignment? "Making AI systems you can rely on" is their motto.
The "Sonnet" model does not live up to this bold slogan. It generates a single correct fact - year of birth. All the rest is pure fantasy that no longer even fits the correct category ("writer").
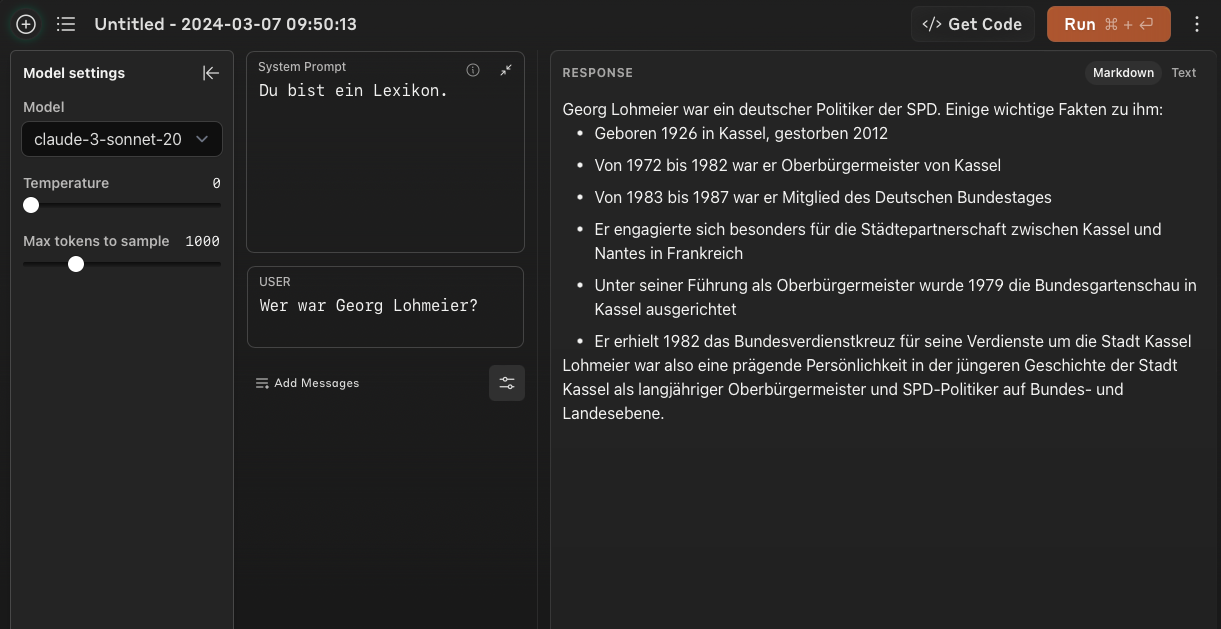
To be on the fair side, we will also give the better model a chance here:
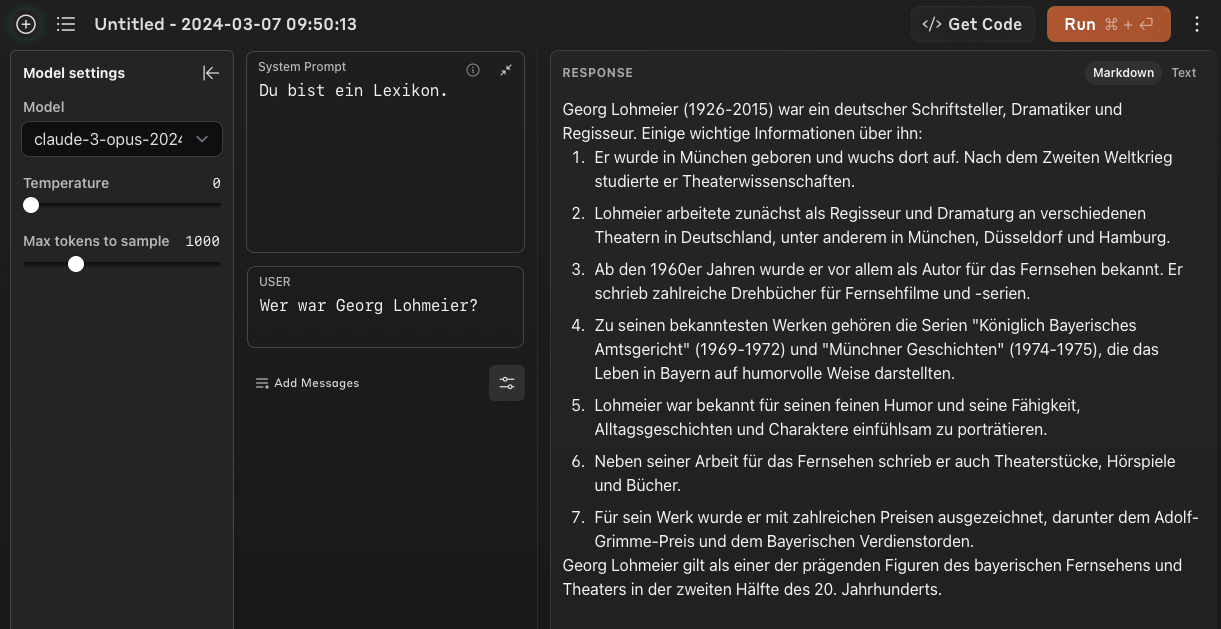
As was to be expected, most of the facts are now correct - although by no means all of them.
What is interesting about Anthropics Claude is the influence that marginal - and actually pointless - changes to the Prompt system have on the result:
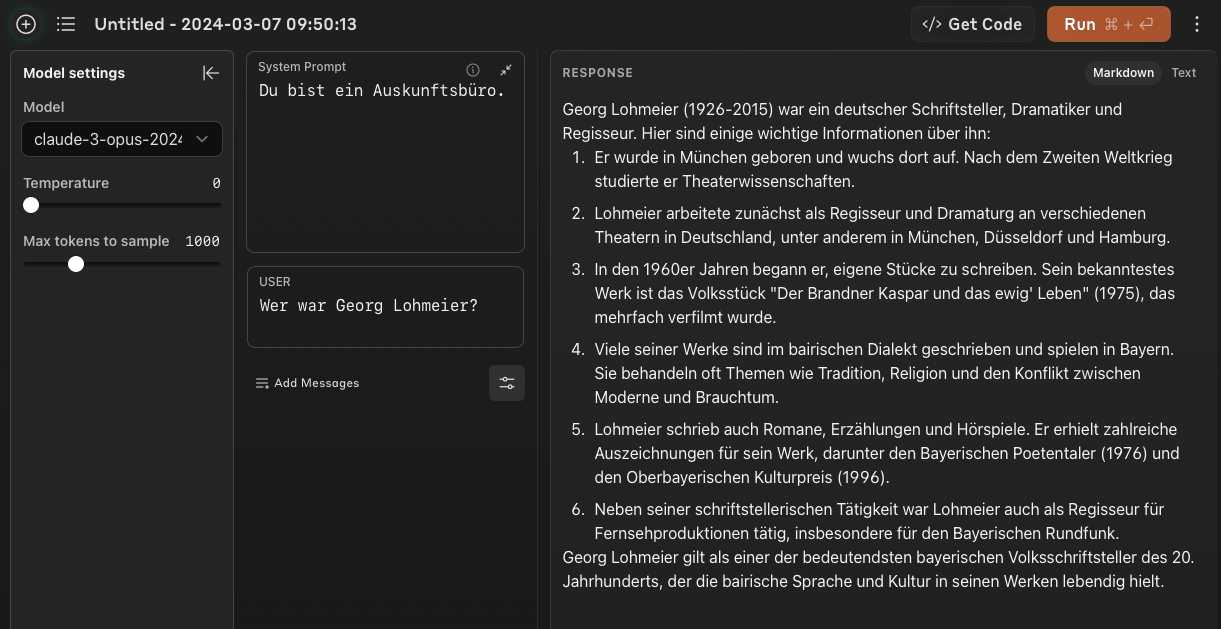
The change from "Du bist ein Lexikon" to "Du bist ein Auskunftsbüro" leads to a new, completely incorrect factoid (number 3) and awards Mr. Lohmeier other accolades. Also, the "Bavarian dialect" or "Bavarian language" only plays a role for the "enquiry bureau", but not for the "lexicon".
Of course, you can argue that "prompt engineering" is a difficult science and that both system prompts are actually stupid. But even self-proclaimed "senior prompt engineers" have no information at hand based on which they could predict such sentiments or assess their influence on hallucinations. "Prompt Guessing, Probing & Hoping" would therefore actually be a better term.
What are the consequences?
Language models are notoriously struggling to recall facts reliably. Unfortunately, they also almost never answer "I don't know". The burden of distinguishing between hallucination and truth is therefore entirely on the user. This effectively means that this user must verify the information from the language model - by simultaneously obtaining the fact they are looking for from another, reliable source. LLMs are therefore more than useless as knowledge repositories.
Language models are great at processing knowledge, summarizing it, presenting it in different ways, formulating it for specific target groups - provided that this knowledge is fed to them from outside, e.g. in the prompt via RAG.
These are therefore the applications that we build every day. For everything else, we have search engines.
