Helpful at all costs - ChatGPT and the end of the software engineer

The world has lost its head over the launch of ChatGPT. I understand that, the power of this new LLM is impressive and has something magical i.e. human especially for non-natives of AI land.
Inevitably, there is a flood of posts and articles about ChatGPT. For the most part - as usual with AI launches - wholehearted applause for the "new era" or dire warnings about the end of one or more professions.
In the case of ChatGPT, this time it is not the turn of stock photographers (Dall-E has already taken care of them), but software developers.
Who needs them when ChatGPT is just as good at writing programs as it is at writing poetry?
The assumption that current LLMs could be a threat to the future of software developers sounds so baseless to me that I'm afraid I have to add one more to the huge list of ChatGPT articles.
First of all: software development, amazingly, does not consist in churning out snippets of code that do individual clear tasks ("sort this list alphabetically"), but in for instance combining many such pieces of code into useful modules and service interfaces. I'm not aware of anyone even attempting to present this task to a conversational AI.
So the only actual question is: To what extent can ChatGPT or its predecessors (good old GPT-3 can already generate code) and successors (Sparrow will surely be able to do this as well) at least unburden and accelerate software developers in their daily work?
At first glance and for simple examples, this actually seems to work to a certain degree:
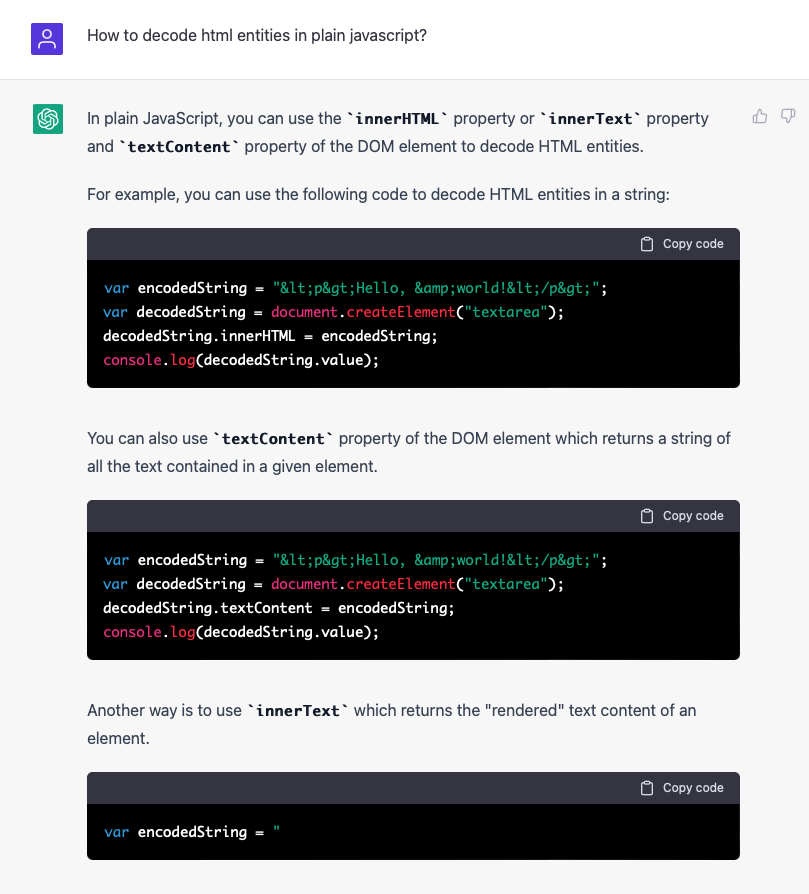
In this case, the fact that you can have ongoing conversations with ChatGPT is helpful in refining the solution:
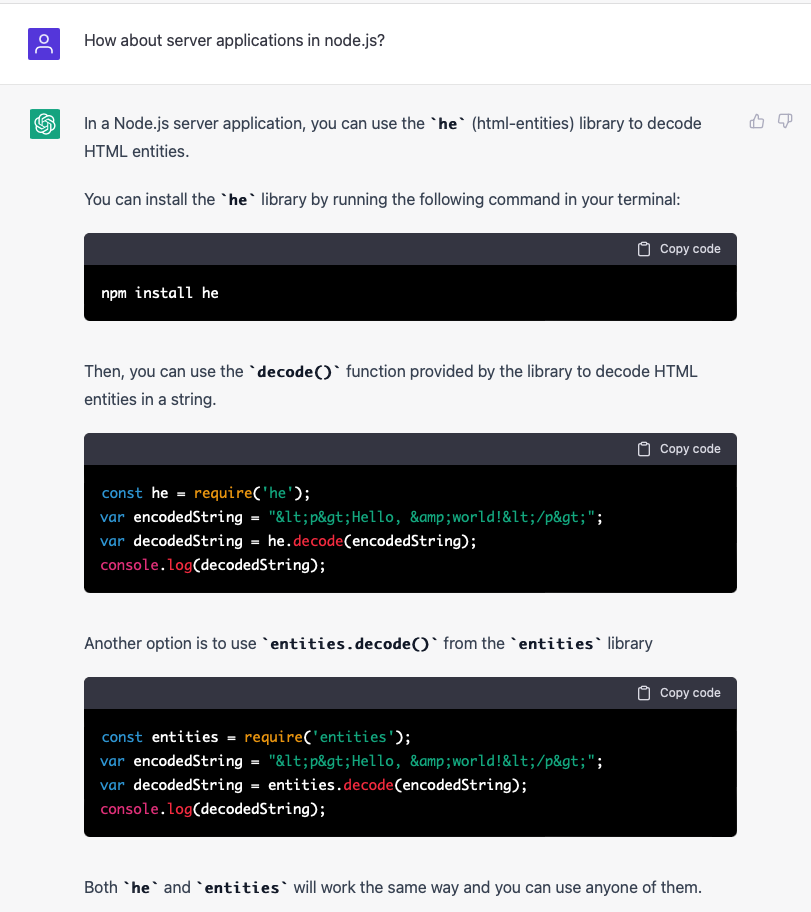
Let's recall at this point that ChatGPT consists of the essence of countless training elements (including many such software snippets) and outputs the most probable "continuation" for each input based on these training elements. This works very well for the Javascript question mentioned above.
But ChatGPT is only trained to generate plausible and probable output, not “true" statements. In its mission to help the user, it can't be bothered with such banalities as correctness. The only thing that matters is the probability of each token.
If we move a bit away from the problems for which presumably large amounts of examples were included in the training, the air becomes thin and so does the answer:

This answer is wrong for two reasons:
- ARRAY_TO_STRING does not accept integer arrays, so the proposed solution is not valid BigQuery SQL.
- Even if it worked, it would not create an array as requested, but a single string value (by joining the array elements using a delimiter).
Obviously, the question was interpreted correctly, but in its eagerness to help, the AI chose to generate lies rather than not answer anything plausible at all.
Let's try to make the question a little more precise, since that worked so well with the Javascript problem:
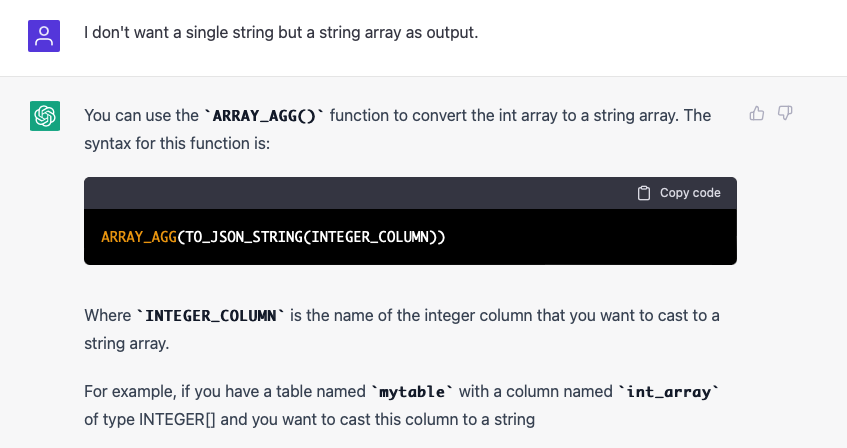
I won't bore readers with an explanation of what this code snippet really does (unlike the one above, it is valid Big Query SQL). In any case, it doesn't do the right thing, it does something rather useless, but consumes a lot of resources.
ChatGPT firmly insists on producing false solutions throughout the conversation in order to be helpful. It reminds me a bit of people you ask for directions and they don't dare admit their ignorance of the area. Instead, they point you in an arbitrary direction. After all, it would be embarrassing to have to admit that they don't know their way around.
So here's my conclusion, as so often a different one from that of many other "experts": No, ChatGPT will not replace software developers or even junior programmers. Maybe it will save some entry-level developers a trip or two to Stackoverflow. But even then, you have to ask yourself if trying out and eliminating such wrong solutions doesn't cost more time on average than the right answers save.
