Ist das der Tod aller weltverändernden AI-Anwendungen?

Seit den frühesten Versuchen, maschinelles Lernen im großen Stil für wirklich kritische Aufgaben einzusetzen, rennen solche Anwendungen immer wieder gegen die gleiche Wand. Gerade, was maschinelles Lernen so magisch wirken lässt, macht es auch manchmal nutzlos: Die Ergüsse künstlicher Intelligenz sind zu oft im engeren und weiteren Sinne unerklärbar.
Damit meine ich nicht, dass wir normalen Erdlinge zu dumm sind, die komplexen Datenstrukturen und Algorithmen zu verstehen, die hinter dem aktuellen AI-Hype stehen (ChatGPT, LamDa, BARD und das Bing-KI-Ding).
Das Problem ist ein anderes und in gewissem Maße ein unabwendbares: Selbst die Experten, die diese Anwendungen geschrieben haben, können nicht nachvollziehen, warum eine bestimmte Eingabe die jeweilige Ausgabe erzeugt.
Das liegt in der Natur der verwendeten Algorithmen: In der klassischen, der sogenannten symbolischen künstlichen Intelligenz, setzt man auf Wissensrepräsentationen und Formeln, mit deren Hilfe nachvollziehbare Schlussfolgerungen aus diesem Wissen gezogen werden. Das heißt, der menschliche Programmierer gibt die Regeln vor, nach denen eine bestimmte Eingabe zu einer Ausgabe führt. Das hat den Vorteil absoluter Nachvollziehbarkeit und Konsistenz, ist aber leider für viele Probleme nicht leistungsfähig genug – bei gleichzeitig sehr hohem Entwicklungsaufwand.
Für nicht-symbolische Probleme, wie z.B. Bilderkennung und Audioanalyse, sind solche Verfahren gänzlich ungeeignet. Hier kommt das maschinelle Lernen zum Zug: Anhand von Trainingsdaten, d.h. “beschrifteten” Beispielexemplaren (z.B. vorkategorisierte Bilder) leitet die KI selber “Regeln” ab. Verschiedene Verfahren nicht-symbolischer KI unterscheiden sich in der Art der “Ableitungsmaschine”.
Maschinelles Lernen mit einer großen Anzahl von Parametern (und entsprechend gigantischen Mengen an Trainingsdaten) erzeugt Modelle, die nicht mehr vorhersehbar und erklärbar sind. Das ist natürlich auch, was den großen Reiz von z.B. ChatGPT ausmacht: die unerklärliche Menschlichkeit seiner Ausgaben, die Menge an Information, auf die es zurückgreifen kann – bis es anfängt zu lügen oder sogar zu streiten und man nichts dagegen machen kann.
Auch Menschen lügen, täuschen, streiten. Ich kann gar nicht zählen, wie oft ich einen Mitmenschen zitiert habe, nur um später festzustellen, dass er mir absoluten Murks erzählt hatte. Das schadet meinem persönlichen Ruf und ich bin mehr und mehr dazu übergegangen, Informationen, die ich von Dritten bekomme, mehrmals zu überprüfen – z.B. durch Internet-Recherchen – bevor ich sie weitergebe. Aber was, wenn ich dafür nun auf einen ChatBot mit zweifelhaftem Wahrheitsempfinden statt einer Suchmaschine angewiesen bin?
Von bestimmten Berufsgruppen wird ein hohes Maß an Verlässlichkeit und Wahrhaftigkeit erwartet: Juristen, Lehrer, Wissenschaftler sehen sich diesem Anspruch mehr als andere ausgesetzt, auch wenn sie ihn oft nicht erfüllen. Aber welches Ergebnis erwarten wir, wenn wir nun gerade im Jura-, Bildungs- und Forschungsumfeld auf künstliche Intelligenz mit zweifelhaftem Faktenwissen setzen wollen?
In einem früheren Berufsleben war ich CEO einer Firma, die in den USA im Bereich “eDiscovery” bzw. “Legal AI” Fuß fassen wollte. An die Diskussionen rund um die Erklärbarkeit und Verlässlichkeit unserer Software kann ich mich gut erinnern.
Und diese Art von Diskussionen gibt es schon lange vor Deep Learning: Die einfachste Anwendung im Bereich eDiscovery ist eine Art “Hot-or-Not-Classifier”, dessen einzige Aufgabe es ist, zu entscheiden, ob ein Dokument für einen Fall relevant sein könnte oder nicht. Wenn potentiell 20 Millionen Firmen-Emails als relevant in Frage kommen, ist solch eine maschinelle Klassifizierung entscheidend dafür, ob man den Fall überhaupt verhandeln kann. Aber welche Fehlerrate ist akzeptabel? Ist es OK, wenn der Classifier nur 80% der wesentlichen Dokumente findet? Hätte ein Jurist in diesem riesigen Heuhaufen mehr gefunden? Was, wenn zusätzlich 5 Millionen Dokumente als relevant angesehen werden, obwohl sie es nicht sind? Wer ist schuld an den vielen abgerechneten Stunden der Anwälte, die diese Dokumente nun lesen müssen?
Und hier handelte es sich um Algorithmen, deren Fehler und Versäumnisse wenigstens zum Teil erklärbar waren, z.B. indem man auf spezifische Beispieldokumente aus der Trainingsphase verweisen konnte, die zu einer Fehlklassifikation geführt hatten.
Dies fällt bei Large Language Models, dem aktuellen Turnierpferd des Deep Learning Hype, völlig weg. Das Modell kann nicht sagen, woher es eine Information bezieht. Und ein Mensch kann höchstens raten, welche Eingabedaten für eine bestimmte Ausgabe verbaut wurden. Vorausgesetzt, er kennt sich in den Trainingsdaten hervorragend aus, womit er dann die KI auch ersetzen könnte.
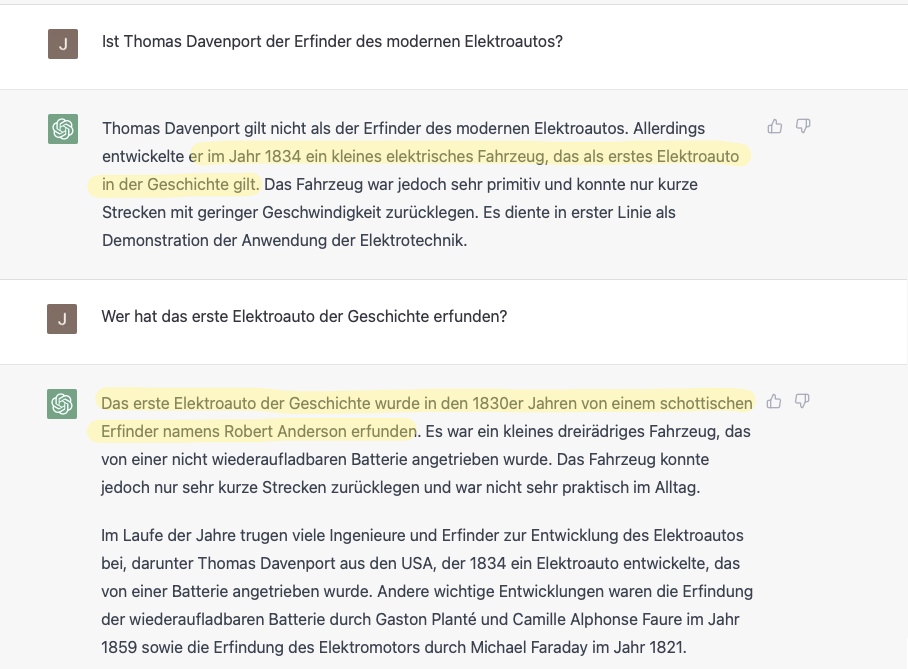
Halten wir also fest: Deep Learning und insbesondere Large Language Models sind in ihren Ausgaben unvorhersehbar und nicht nachvollziehbar, sprichwörtliche Black Boxes. Mit diesen Technologien kann man also keine Software für Anwendungsfälle herstellen, die auf Verlässlichkeit, Angabe von Quellen oder Vollautomation (kein Mensch mehr in der Schleife) angewiesen sind. Vor diesem Hintergrund bin ich auch überzeugt, dass die klassische Suchmaschine noch lange nicht tot ist. Der Bias und die Lügen in den durchsuchten Dokumenten reichen mir völlig aus, auch ohne dass noch eine Dialogmaschine ihren unvorhersehbaren Senf dazu gibt. Die aktuellen Versuche, z.B. GPT mit Bing bzw. Bard mit dem Google-Suchindex zu verheiraten, weben zwar Quellenangaben und Suchergebnisse in die Konversation mit ein, das löst aber das ursprüngliche Problem nicht - wie sich nach ein paar Beispielanfragen schmerzhaft zeigt.
Detaillierte Hintergrundinformationen zu Large Language Models und ihren Eigenschaften finden sich in unserem YouTube-Video zum Thema:
